(Re)using EU controlled vocabularies to enrich Semantic Government Vocabulary
On Friday 28th May speaker Michal Med held the Open Mic session with the topic was "(Re)using EU controlled vocabularies to enrich Semantic Government Vocabulary". Semantic modeling of the legislative processes and documents at the national level in the Czech Republic is done using Assembly line and the result is stored in a form of RDF vocabularies as Semantic Government Vocabulary (SGoV). The European Union also provides top level vocabularies for description of legislative processes and legislation itself. This speech sums up how are those vocabularies published, what is their content and which of them can be reused.
EU Vocabularies
Publication Office of the European Union publishes Vocabularies distinguished as Controlled vocabularies and Models. Controlled vocabularies are defined as “Controlled vocabularies provide a consistent way to describe data. They are standardized and organized arrangements of words and phrases presented as alphabetical lists of terms or as thesauri and taxonomies with a hierarchical structure of broader and narrower terms.” Models are defined as “Models are primal in the creation or conceptualization of controlled vocabularies (ontologies). Some are used for the validation of vocabularies (schemas), while others can be derived from them. Still others define how given vocabularies are to be useful for subsequent IT purposes (application profiles).”
Controlled vocabularies
Contains five types of vocabularies:
- Authority tables – used to harmonise and standardise the codes and associated labels used in various environments and in facilitating data exchanges between the institutions,
- Thesauri – controlled and structured vocabulary with concepts represented by labels with a hierarchical structure of broader and narrower terms (multilingual),
- ATTO tables – internal application of PO that regroups translations in different languages, public available ONLY metadata related tables used by EUR-Lex,
- Alignments – given concept from one vocabulary may have a level of correspondence with a concept in different vocabulary,
- Taxonomies – set of controlled vocabulary terms organized in hierarchical structure, referred as a tree. Non preferred labels and synonyms are not allowed.

Models
Models contain of four types of vocabularies:
- Schemas – XML schemas, a machine readable representation of a data set,
- Ontologies – formal specification designed to delimit and group instances/concepts based on their common class and thus formalizing a domain,
- Presentation style sheets – style sheets are meant for transformation of controlled vocabularies in the human readable (document) form. EU Publications Office uses CSS files for this,
- Application profiles – describe how to apply standards in particular domains or applications.

From the semantic point of view, interested subgroups are Taxonomies, Thesauri and Ontologies. The speech focuses on semantic vocabularies that could be reused in Semantic Governmental Vocabulary. A lot of vocabularies published as EU Vocabularies are for the internal usage, or describe internal processes. Interesting vocabularies describing legislation and its processes are e.g. EuroVoc and ELI.
EuroVoc is a multidisciplinary thesaurus covering the activities of the EU. It contains terms in 24 EU languages and three languages of candidate countries.
The European Legislation Identifier (ELI) is a system to make legislation available online in a standardized format in order to access it and reuse and exchange it across borders. It incudes technical specification on web identifiers in the URI form, metadata specification and a specific language for exchanging legislation in machine readable formats. It is used for detailed description of legislation in EUR-Lex web application.
ELI stands on three pillars:
- Identification of legislation: URI templates at the European, national and regional levels based on a defined set of components,
- Properties describing each legislative act: Definition of a set of metadata and its expression in a formal ontology,
- Serialisation of ELI metadata elements: Integration of metadata into the legislative websites using RDFa.
Technical solution
Publication Office uses VocBench for the creation of the semantic content. For the visualization of the tools, it uses ShowVoc, a tool using Apache Karaf server and Semantic TUrkey as RDF services platform.
ISA2 Core Vocabularies
Next to the EU Vocabularies, there is a ISA2Core Vocabulary created and published by the SEMIC action by the European Commission.
Core vocabularies are simplified, reusable and extensible data models that capture the fundamental characteristics of an entity in a context-neutral manner. It is intended for usage and extension by the public administration in order to exchange information between systems, data integration, data publication and development of new systems. ISA2 Core Vocabularies consists of the following vocabularies:
- Core Person,
- Core Business,
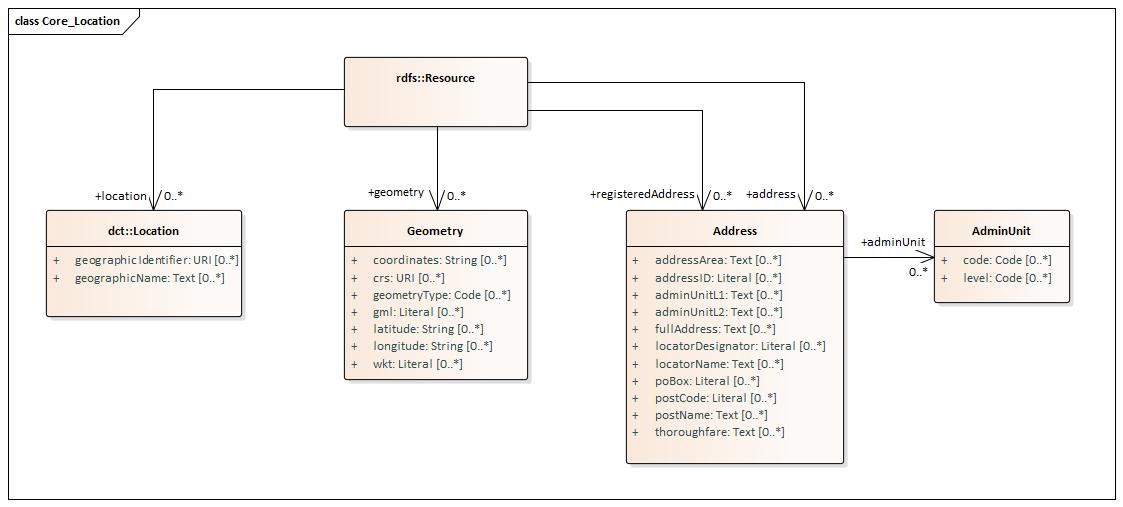
- Core Location,
- Core Criterion and Core Eidence,
- Core Public Organisation.
All the vocabularies are publicly available in GitHub, containing documentation, UML models and vocabularies itself in the TTL serialization.
The presentation slides are available at this link.
Links: Further reading: