An introduction to SPipes modules and their usage
On the 17th March, speaker Matěj Kulich held the presentation about the SPipes modules. It is a follow-up presentation on SPipes given in November by Miroslav Blaško, going into more details regarding SPipes modules.
The abstract
SPipes Modules is a collection of specific module types used in SPipes, a tool for managing semantic pipelines defined in RDF. These modules are stateless transformations of input data that can be instantiated in a pipeline. They are implemented in Java and defined in RDF.
The presentation focuses on SPipes modules and their usage. These modules are pipeline building blocks that perform specific tasks and are implemented in Java. The input and output are RDF data which are manipulated with the JENA framework. Modules can also be validated with input and output validation constraints. Each validation constraint is a SPARQL query.
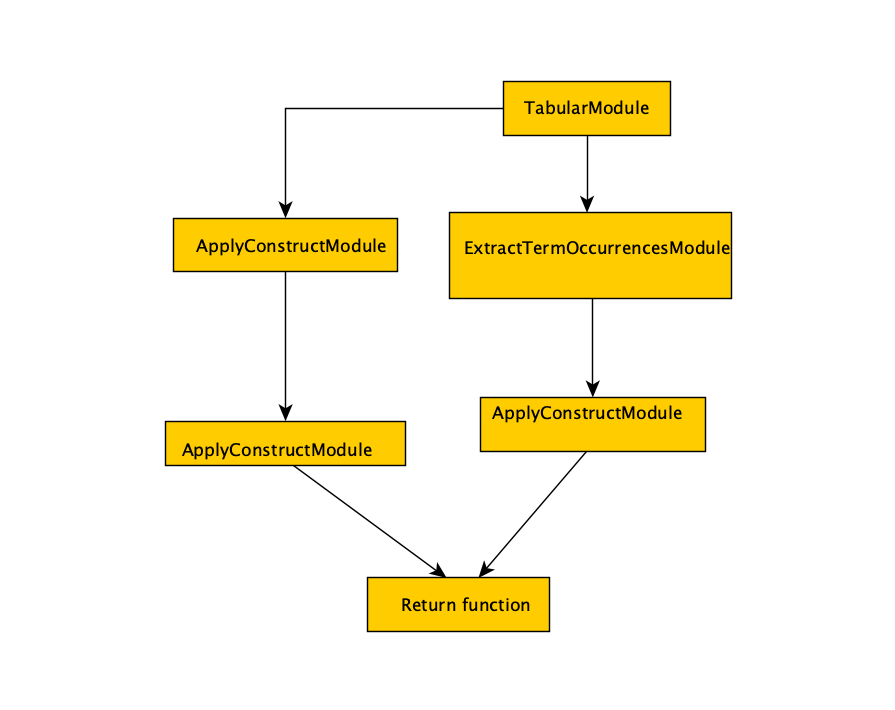
The presentation also discussed several modules of SPipes, such as the Apply Construct module that applies SPARQL CONSTRUCT queries to RDF data, and the Bind by Select module that runs a SPARQL select query and binds all result variables of the first matching result set. The Text Analysis module annotates RDF literals with an analysis service, while the Extract Term Occurrences module extracts term occurrences from annotated literals of input RDF. The RDF2CSV module is responsible for converting input RDF data into a CSV format, while the Tabular module enables converting CSV or TSV data into RDF data.
Finally, the presentation covered general info about modules, and the creation of custom modules using the s-pipes-module-archetype. There was shown generating a new module and pretty simple pipeline which uses Apply Construct Module and Tabular Module. The presentation did not cover all modules, it provided an overview of some of the most important ones.
The presentation slides are available at this link.